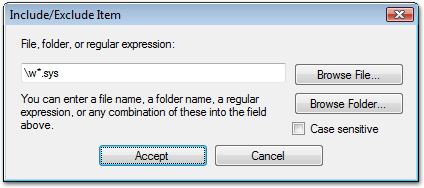
| Browse File: | Browse for a specific file to include or exclude. |
| Browse Folder: | Browse for a specific folder to include or exclude. |
| Case Sensitive: | If checked, regular expressions will be matched using case-sensitive method. Case will be ignored otherwise. |
\w*\.sys - will match all files which have a .sys extension.
\p{Nd} - will match all files or folder which have at least one digit in the name.
Below excerpts define how regular expressions are matched and interpreted.
| [character_group] | (Positive character group.) Matches any character in the specified character group. The character group consists of one or more literal characters, escape characters, character ranges, or character classes that are concatenated. For example, to specify all vowels, use [aeiou]. To specify all punctuation and decimal digit characters, code [\p{P}\d].
| |
| [^character_group] | (Negative character group.) Matches any character not in the specified character group. The character group consists of one or more literal characters, escape characters, character ranges, or character classes that are concatenated. The leading carat character (^) is mandatory and indicates the character group is a negative character group instead of a positive character group. For example, to specify all characters except vowels, use [^aeiou]. To specify all characters except punctuation and decimal digit characters, use [^\p{P}\d].
| |
| [firstCharacter-lastCharacter] | (Character range.) Matches any character in a range of characters. A character range is a contiguous series of characters defined by specifying the first character in the series, a hyphen (-), and then the last character in the series. Two characters are contiguous if they have adjacent Unicode code points. Two or more character ranges can be concatenated. For example, to specify the range of decimal digits from '0' through '9', the range of lowercase letters from 'a' through 'f', and the range of uppercase letters from 'A' through 'F', use [0-9a-fA-F].
| |
| . | (The period character.) Matches any character except \n. Note that a period character in a positive or negative character group (a period within square brackets) is treated as a literal period character, not a character class.
| |
| \p{name} | Matches any character in the Unicode general category or named block specified by name (for example, Ll, Nd, Z, IsGreek, and IsBoxDrawing).
| |
| \P{name} | Matches any character not in Unicode general category or named block specified in name.
| |
| \w | Matches any word character. Equivalent to the Unicode general categories [\p{Ll}\p{Lu}\p{Lt}\p{Lo}\p{Nd}\p{Pc}\p{Lm}]. If ECMAScript-compliant behavior is specified with the ECMAScript option, \w is equivalent to [a-zA-Z_0-9].
| |
| \W | Matches any nonword character. Equivalent to the Unicode general categories [^\p{Ll}\p{Lu}\p{Lt}\p{Lo}\p{Nd}\p{Pc}\p{Lm}]. If ECMAScript-compliant behavior is specified with the ECMAScript option, \W is equivalent to [^a-zA-Z_0-9].
| |
| \s | Matches any white-space character. Equivalent to the escape sequences and Unicode general categories [\f\n\r\t\v\x85\p{Z}]. If ECMAScript-compliant behavior is specified with the ECMAScript option, \s is equivalent to [ \f\n\r\t\v].
| |
| \S | Matches any non-white-space character. Equivalent to the escape sequences and Unicode general categories [^\f\n\r\t\v\x85\p{Z}]. If ECMAScript-compliant behavior is specified with the ECMAScript option, \S is equivalent to [^ \f\n\r\t\v].
| |
| \d | Matches any decimal digit. Equivalent to \p{Nd} for Unicode and [0-9] for non-Unicode, ECMAScript behavior.
| |
| \D | Matches any nondigit character. Equivalent to \P{Nd} for Unicode and [^0-9] for non-Unicode, ECMAScript behavior.
|
| Lu | Letter, Uppercase
| |
| Ll | Letter, Lowercase
| |
| Lt | Letter, Titlecase
| |
| Lm | Letter, Modifier
| |
| Lo | Letter, Other
| |
| Mn | Mark, Nonspacing
| |
| Mc | Mark, Spacing Combining
| |
| Me | Mark, Enclosing
| |
| Nd | Number, Decimal Digit
| |
| Nl | Number, Letter
| |
| No | Number, Other
| |
| Pc | Punctuation, Connector
| |
| Pd | Punctuation, Dash
| |
| Ps | Punctuation, Open
| |
| Pe | Punctuation, Close
| |
| Pi | Punctuation, Initial quote (may behave like Ps or Pe depending on usage)
| |
| Pf | Punctuation, Final quote (may behave like Ps or Pe depending on usage)
| |
| Po | Punctuation, Other
| |
| Sm | Symbol, Math
| |
| Sc | Symbol, Currency
| |
| Sk | Symbol, Modifier
| |
| So | Symbol, Other
| |
| Zs | Separator, Space
| |
| Zl | Separator, Line
| |
| Zp | Separator, Paragraph
| |
| Cc | Other, Control
| |
| Cf | Other, Format
| |
| Cs | Other, Surrogate
| |
| Co | Other, Private Use
| |
| Cn | Other, Not Assigned (no characters have this property)
|
| C | (All control characters) Cc, Cf, Cs, Co, and Cn.
| |
| L | (All letters) Lu, Ll, Lt, Lm, and Lo.
| |
| M | (All diacritic marks) Mn, Mc, and Me.
| |
| N | (All numbers) Nd, Nl, and No.
| |
| P | (All punctuation) Pc, Pd, Ps, Pe, Pi, Pf, and Po.
| |
| S | (All symbols) Sm, Sc, Sk, and So.
| |
| Z | (All separators) Zs, Zl, and Zp.
|
| ^ | Specifies that the match must occur at the beginning of the string or the beginning of the line. For more information, see the Multiline option in Regular Expression Options.
| |
| $ | Specifies that the match must occur at the end of the string, before \n at the end of the string, or at the end of the line. For more information, see the Multiline option in Regular Expression Options.
| |
| \A | Specifies that the match must occur at the beginning of the string (ignores the Multiline option).
| |
| \Z | Specifies that the match must occur at the end of the string or before \n at the end of the string (ignores the Multiline option).
| |
| \z | Specifies that the match must occur at the end of the string (ignores the Multiline option).
| |
| \G | Specifies that the match must occur at the point where the previous match ended. When used with Match.NextMatch(), this ensures that matches are all contiguous.
| |
| \b | Specifies that the match must occur on a boundary between \w (alphanumeric) and \W (nonalphanumeric) characters. The match must occur on word boundaries (that is, at the first or last characters in words separated by any nonalphanumeric characters). The match can also occur on a word boundary at the end of the string.
| |
| \B | Specifies that the match must not occur on a \b boundary.
|
| * | Specifies zero or more matches; for example, \w* or (abc)*. Equivalent to {0,}.
| |
| + | Specifies one or more matches; for example, \w+ or (abc)+. Equivalent to {1,}.
| |
| ? | Specifies zero or one matches; for example, \w? or (abc)?. Equivalent to {0,1}.
| |
| {n} | Specifies exactly n matches; for example, (pizza){2}.
| |
| {n,} | Specifies at least n matches; for example, (abc){2,}.
| |
| {n,m} | Specifies at least n, but no more than m, matches.
| |
| *? | Specifies the first match that consumes as few repeats as possible (equivalent to lazy *).
| |
| +? | Specifies as few repeats as possible, but at least one (equivalent to lazy +).
| |
| ?? | Specifies zero repeats if possible, or one (lazy ?).
| |
| {n}? | Equivalent to {n} (lazy {n}).
| |
| {n,}? | Specifies as few repeats as possible, but at least n (lazy {n,}).
| |
| {n,m}? | Specifies as few repeats as possible between n and m (lazy {n,m}).
|
| | | Matches any one of the terms separated by the | (vertical bar) character; for example, cat|dog|tiger. The leftmost successful match wins.
| |
| (?(expression)yes|no) | Matches the "yes" part if the expression matches at this point; otherwise, matches the "no" part. The "no" part can be omitted. The expression can be any valid subexpression, but it is turned into a zero-width assertion, so this syntax is equivalent to (?(?=expression)yes|no). Note that if the expression is the name of a named group or a capturing group number, the alternation construct is interpreted as a capture test (described in the next row of this table). To avoid confusion in these cases, you can spell out the inside (?=expression) explicitly.
| |
| (?(name)yes|no) | Matches the "yes" part if the named capture string has a match; otherwise, matches the "no" part. The "no" part can be omitted. If the given name does not correspond to the name or number of a capturing group used in this expression, the alternation construct is interpreted as an expression test (described in the preceding row of this table).
|
(c) 2008 Ketara Software